


On one side, you have an AI that feels like a strong engineer moving quickly—usually right, but occasionally skipping integration details. On the other, you have a model that feels like someone who carefully read your entire repo before touching a single line of code. Which one are you trusting with your next refactor? I’m Millie, an AI tool reviewer at 19pine.ai. In this Claude vs ChatGPT for coding breakdown, I pit the top 2026 models against each other across four real-world buckets: generation, debugging, refactoring, and documentation. The differences go way beyond just 'vibes'—they show up exactly where busy professionals feel it most.
How we compared them
I didn't run a lab-grade benchmark suite like SWE-bench. I ran what I actually run into: "Why is this failing in production?", "Please refactor this without breaking the tests," and "Can you write the thing I've been avoiding all week?"
Test tasks: code generation, debugging, refactoring, documentation
I used four buckets because they map to how coding help shows up in real life:
- Code generation: quick utilities and slightly-too-big features (the stuff you'd normally knock out in a focused hour, if you had one).
- Debugging: trace an error from logs, explain the likely cause, propose fixes, and call out what to verify.
- Refactoring/code review: reorganize code for readability, reduce duplication, tighten types, and flag risk.
- Documentation: docstrings, README sections, usage examples, and "tell Future Me what this does."
For each task, I scored two things that matter when you're time-pressured:
- First-pass correctness (how often I can paste and run without a detour)
- Time-to-fix when it's not correct (is the mistake shallow or does it send me on a hunt?)
Models tested
For the Anthropic vs OpenAI coding angle, I stuck to the models professionals are realistically using in 2026:
- Claude: Sonnet 4.6 (my default "balanced" pick), Opus 4.6 (for heavier reasoning), and Haiku 4.5 (for lightweight prompts)
- ChatGPT/OpenAI: GPT-5.4 (most capable), GPT-5 and other models (general), GPT-5 mini (fast/cheap)
I leaned on Sonnet 4.6 vs ChatGPT (typically GPT-5/GPT-5.4) for most head-to-heads because that's the "daily driver" comparison people actually mean when they ask. Keeping up with the latest ChatGPT release notes ensures you know exactly which version you are interacting with.
Code generation — simple vs complex tasks
If all you do is generate small chunks of code, you can stop reading now: both are good. The real difference shows up when the ask becomes multi-step, multi-file, or easy to misunderstand.
Boilerplate and simple functions: both strong
For quick wins, regex helpers, small API handlers, one-off scripts, basic CRUD scaffolding, both Claude and ChatGPT produce competent output fast.
What I noticed in practice:
- ChatGPT tends to be slightly more "ready to run" in popular stacks, especially when the request is mainstream ("Express route with validation," "React hook for X," "Python script to parse Y"). It often anticipates the surrounding glue code.
- Claude tends to be a bit more careful about what you asked versus what it assumes. When my prompt was specific (constraints, naming, interfaces), Claude followed it more literally.
If you're choosing the best AI for coding 2026 for boilerplate alone, the gap is small enough that your choice will come down to price, workflow, and whether you prefer a more conversational vs more structured response style.
Complex multi-file tasks: where they diverge
Here's where I stopped thinking "these are interchangeable."
When the task spans multiple files, say, "add a new auth flow, update middleware, adjust tests, update docs", the model has to keep a lot straight: state, interfaces, side effects, and what not to break.
- Claude (especially with larger context) is calmer when there's a lot of code pasted in. It's better at respecting existing patterns and not inventing new architecture mid-stream. If I fed it a big chunk of existing codebase context, it was less likely to forget an earlier constraint.
- ChatGPT is very capable here too, but I saw more "confident drift", where it proposes a sensible approach that subtly doesn't match the existing code style, or it updates File A but forgets a small counterpart change in File C.
The practical takeaway: for multi-file changes, Claude felt more like someone who read the repo before touching anything. ChatGPT felt more like a strong engineer moving quickly, usually right, occasionally skipping a small integration detail.
Debugging and error fixing
Debugging is where I'm least patient. If I paste an error trace, I'm not looking for a textbook. I want: likely cause, what to check, and a fix that won't create a new problem.
Explanation quality comparison
Both models can explain errors. The difference is whether the explanation helps you act.
- Claude tends to give more structured reasoning: "Here are the top 3 likely causes, here's how to confirm each, here's the minimal fix." It's not perfect, but it wastes less of my time.
- ChatGPT can be excellent at walking through a chain of causality, especially if you keep it in a tight loop ("No, I already checked that, what next?"). But on the first pass, it sometimes gives a broader spread of possibilities.
In my notes, Claude won more often on "first response I can use," while ChatGPT won more often on "I can talk my way to the answer" if I had time to iterate.
Edge case detection
This is the part most people miss, because the code works until it doesn't.
When I asked both to fix a bug and also call out edge cases (null inputs, race conditions, pagination off-by-one, timezone weirdness, retry storms), Claude more reliably surfaced the unsexy risks. Not always, but more consistently.
ChatGPT did catch edge cases too, especially when I explicitly asked it to generate tests that would fail on the current implementation. But I had to nudge it more: "List edge cases," "Now write tests," "Now explain what's still unhandled."
If your day is packed and you want the model to be the paranoid reviewer you don't have time to be, Claude had the advantage in my debugging runs.
Refactoring and code review
Refactoring is where an AI can either save you hours or quietly create a mess you only notice a week later.
Claude's structured output advantage
Claude is consistently good at producing refactors in a reviewable way. When I asked for:
- a step-by-step plan
- a diff-like breakdown (what changes where)
- and the "why" behind each change
…it complied more cleanly. It's easier to scan. Easier to hand to a teammate. Easier to sanity-check before you merge.
This matters if you're refactoring under real constraints: "Don't change external behavior," "Keep public APIs stable," "Avoid adding dependencies." Claude was less likely to casually violate those guardrails.
ChatGPT's iterative conversation strength
ChatGPT's superpower here is the back-and-forth. It's good at acting like a collaborative reviewer:
- "I don't like this abstraction, show me an alternative."
- "Ok, but keep it closer to the existing style."
- "Now optimize for readability over cleverness."
If you're the type of person who refactors by conversation, tight feedback loops, small commits, ChatGPT feels natural. It's also very good at generating variations: three options, tradeoffs, and a recommendation.
So in the claude vs chatgpt coding comparison for refactoring: Claude wins for clean, structured deliverables: ChatGPT wins for iterative exploration.
Pricing for developers
Pricing is the part I always read twice because it's where "fun experiment" turns into "why is this line item here every month?"
API cost per million tokens
Here are the 2026 developer API rates I used for the math (input/output per 1M tokens):
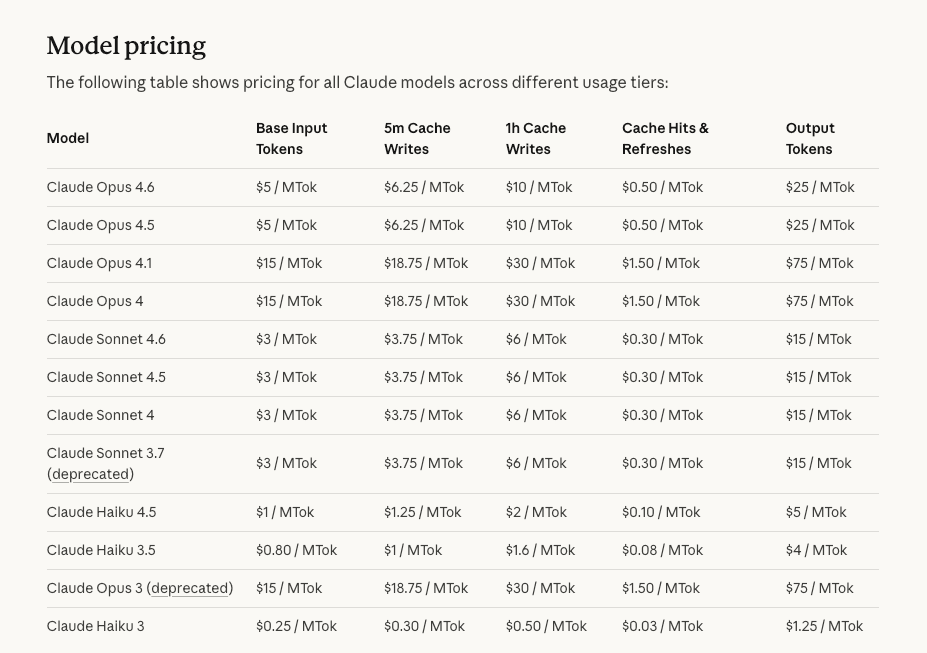
- Haiku 4.5: $1 / $5
- Sonnet 4.6: $3 / $15
- Opus 4.6: $5 / $25
- Prompt caching can save ~90% on repeated context: batch API ~50% off
- GPT-5 mini: $0.25 / $2
- GPT-5: $1.25 / $10
- GPT-5.4: $2.5 / $15
- Batch API ~50% off: cached inputs ~10x cheaper
In plain English: OpenAI is generally cheaper for simple tasks, especially if you're cost-sensitive at scale. Claude's pricing makes more sense when you're buying "fewer mistakes" on complex prompts or using big context windows effectively.
Plus vs Pro value for coders
For subscriptions, the relevant comparison is simple because both sit around $20/month:
- ChatGPT Plus tends to win on ecosystem breadth: more integrations, multimodal features, image generation, and lots of "it probably supports this" convenience.
- Claude Pro is unusually compelling if you code a lot because it includes Claude Code (agent-style, multi-step help) and a 200K context workflow that's genuinely useful when you're juggling long files, specs, and diffs.
If you're a coder who regularly pastes large context and wants the tool to remember it without constant re-grounding, Claude Pro's value proposition is straightforward. If you ever need to change your tech stack, it is easy to learn how to cancel your ChatGPT subscription, whether on desktop or directly on your iPhone. You can even choose to completely delete your ChatGPT account if you decide to fully migrate to Claude.
Decision matrix by task type
This is the part you actually came for: what I'd pick depending on the job in front of me.
Choose Claude if
You'll probably prefer Claude (Sonnet/Opus) when:
- You're dealing with large context (long files, specs, multi-module work) and you want fewer "wait, we already said…" moments.
- You need structured output for refactors, reviews, or implementation plans you can follow without rereading three times.
- You're debugging something hairy and want a model that's better at edge cases and risk scanning.
- You value "reads the room" literalness, Claude is less likely to go off-script when you set constraints.
If your question is basically, "Can the AI handle the annoying stuff for me without me supervising it like a toddler?" Claude is often the calmer choice.
ChatGPT (GPT-5 / GPT-5.4) is the better fit when:
- You want rapid iteration and you like solving problems through dialogue: propose, critique, revise, repeat.
- Your tasks are common-stack code generation and you want lots of ready-to-run snippets and variations.
- You care about cost efficiency for high-volume, well-scoped prompts, especially with mini models and caching.
- You need multimodal help (images, diagrams, broader toolchain workflows) as part of your dev day.
For a lot of teams, the answer isn't "one or the other." It's "ChatGPT for quick loops, Claude for deep work."
Verdict
If you're asking me, Millie, with deadlines looming, a to-do board that never shuts up, and just enough time between calls to either fix the bug or ignore it for another week, here's my colleague-to-colleague verdict on Claude vs ChatGPT for coding:
- For simple code generation, it's basically a tie. Pick the one that fits your budget and your workflow.
- For complex, multi-file work and anything that benefits from long context, Claude (especially Sonnet/Opus) is the one I trust more to stay aligned with the code I already have.
- For debugging, Claude is often more immediately actionable: ChatGPT becomes excellent if you have time to iterate and steer.
- For refactoring, Claude gives cleaner, more review-friendly output: ChatGPT is great when you want to workshop options.
- For developer pricing, OpenAI usually wins on cheap throughput: Claude wins when it prevents expensive mistakes.
I'll be honest, I went in expecting very little difference beyond vibes. But the difference shows up in the exact place busy professionals feel it: how often you have to step in and manage the tool.
I've laid out everything you need. The rest is up to you.
We know developers value automation for complex workflows. Pine AI brings that exact efficiency to your personal life by autonomously handling bill negotiations, refunds, and cancellations. See how our completion agent can save you hours of administrative headaches today.
Frequently Asked Questions: Claude vs ChatGPT for Coding
Claude vs ChatGPT for coding: which is better overall in 2026?
For simple code generation, it’s close to a tie—both produce solid boilerplate and small utilities. The gap shows up in complex, multi-file work and long-context tasks, where Claude (Sonnet/Opus) stays aligned with existing repo patterns more reliably. ChatGPT shines when you want rapid, conversational iteration.
Is Claude or ChatGPT more “ready-to-run” for common-stack code generation?
ChatGPT is often slightly more ready-to-run for mainstream stacks (Express, React, common Python scripts) because it anticipates surrounding glue code. Claude tends to follow your stated constraints more literally—naming, interfaces, and boundaries—so it’s strong when you need exact adherence rather than helpful assumptions.
Which one fixes bugs faster: Claude vs ChatGPT for coding and debugging?
Claude’s debugging responses are typically more immediately actionable: top likely causes, how to confirm each, and a minimal fix. ChatGPT can be excellent too, especially if you iterate (“I checked that—what next?”), but its first pass may explore a wider set of possibilities, which can cost time when you’re rushed.
What’s better for refactoring and code review: Claude or ChatGPT?
Claude usually produces cleaner, more review-friendly refactors—step-by-step plans, diff-like breakdowns, and clear “why” explanations—while respecting guardrails like stable APIs and no new dependencies. ChatGPT is great for workshop-style refactoring: multiple options, tradeoffs, and quick revisions through back-and-forth.
Is ChatGPT cheaper than Claude for developers using the API?
Often yes for throughput and well-scoped tasks. In the 2026 rates cited, GPT-5 mini is very low-cost, and OpenAI’s pricing generally favors high-volume usage. Claude can be cost-effective when long context and fewer mistakes matter more, especially with prompt caching that reduces repeated-context costs.






